Vector Database ve RAG Nedir?
Yapay zekâ ile “dokümanlarıma bakıp doğru cevap versin” dediğiniz an, iki kritik kavram karşınıza çıkar: Vector Database (Vektör Veritabanı) ve RAG (Retrieval-Augmented Generation). Bu yazıda, teknik geçmişi olmayan biri için bile anlaşılır şekilde; ne olduklarını, neden gerekli olduklarını ve birlikte nasıl çalıştıklarını adım adım anlatacağım.
1) Neden Vector DB ve RAG’e İhtiyaç Var?
ChatGPT gibi büyük dil modelleri (LLM’ler) güçlüdür; ancak tek başlarına şu problemlere takılır:
-
Kurum içi dokümanlarınıza otomatik erişemezler (PDF, Word, Notion, KB sayfaları, intranet vb.).
-
Büyük doküman havuzunu “hafıza” gibi sürekli tutmazlar.
-
Bazen uydurma veya yanlış cevap üretebilirler (hallucination).
Özetle şunu istersiniz:
“Model, benim dokümanlarıma dayanarak cevap versin; kafasına göre tahmin yürütmesin.”
İşte RAG tam olarak bunu sağlar.
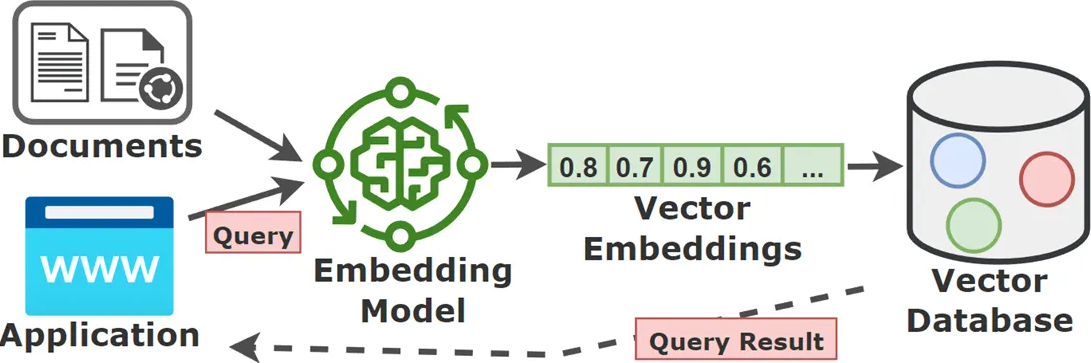
2) Embedding (Vektör) Nedir?
Bir metni (cümle, paragraf, sayfa) alıp onu sayılardan oluşan bir diziye çevirme işlemine embedding denir. Bu sayı dizisi “vektör” olarak adlandırılır.
Buradaki amaç şudur:
Anlamca benzer metinler, matematiksel olarak da birbirine yakın olsun.
Örnek:
-
“Ekran kartı ısısı normal mi?”
-
“GPU sıcaklık değeri kaç olmalı?”
Kelimeler farklı olsa da anlam aynı. Embedding sayesinde sistem bu iki soruyu “benzer” görür.
3) Vector Database (Vektör Veritabanı) Nedir?
Klasik arama (SQL veya metin araması) çoğunlukla şu mantıktadır:
-
“Bu kelime dokümanda geçiyor mu?”
Vector Database ise şunu yapar:
-
“Bu sorunun anlamına en yakın içerikler hangileri?”
Yani anahtar kelime araması değil, anlamsal arama (semantic search) yapar.
Vector DB genelde şunları saklar:
-
Parçanın metni (text)
-
Parçanın embedding’i (vector)
-
Kaynak bilgileri (metadata: dosya adı, sayfa, tarih, kategori, yetki etiketi vb.)
Böylece bir soru geldiğinde, “en benzer” parçaları milisaniyeler içinde bulur.
4) RAG Nedir? (Retrieval-Augmented Generation)
RAG, Türkçeye en basit haliyle şöyle çevrilebilir:
“Önce ilgili bilgiyi bul, sonra modeli o bilgiyle konuştur.”
RAG iki aşamalı çalışır:
A) Retrieval (Bulma)
-
Kullanıcı soru sorar
-
Soru embedding’e çevrilir
-
Vector DB’de arama yapılır
-
En alakalı 3–10 parça (top-k) alınır
B) Generation (Cevap Üretme)
Bulunan parçalar modele “kanıt” olarak verilir ve modelden şunlar istenir:
-
Sadece bu bilgilere dayanarak cevapla
-
Kaynak dışına çıkma
-
Bilgi yoksa “bulamadım” de
Sonuç: Model, uydurmak yerine dokümana dayalı cevap verir.
5) RAG Sistemi Nasıl Kurulur? (Basit Akış)
Bir RAG sistemini gözünüzde canlandırmak için en pratik yol, 3 parçalı bir akış düşünmektir:
1) Veri Hazırlama (Ingestion)
-
PDF/Word/HTML/CSV gibi kaynaklardan metin çıkarılır
-
Metin temizlenir (gereksiz tekrarlar, bozuk karakterler vb.)
-
Metin, küçük parçalara bölünür (chunking)
Chunking neden önemli?
-
Çok büyük parça: Alakasız bilgi taşır
-
Çok küçük parça: Bağlam kopar
Genelde 300–800 token aralığı iyi bir başlangıçtır.
2) İndeksleme (Indexing)
-
Her chunk için embedding çıkarılır
-
Vector DB’ye kayıt edilir (metin + embedding + metadata)
3) Soru-Cevap (Query Time)
-
Kullanıcı sorusu embedding’e çevrilir
-
Vector DB benzer chunk’ları getirir
-
Model, bu chunk’ları referans alarak cevap üretir
6) “Normal Arama Varken Neden Vector Arama?”
Çünkü normal arama şunlarda zorlanır:
-
Eş anlamlı kelimeler (ısınma/sıcaklık/termal)
-
Yazım ve dil farklılıkları
-
Teknik metinlerde terminoloji farkı (SKU vs ürün adı)
-
Kullanıcının sorusu günlük dildeyken doküman daha resmî bir dille yazılmış olabilir
Vector arama, anlam üzerinden gittiği için bu farkları daha iyi tolere eder.
7) RAG Kalitesini Belirleyen Kritik Noktalar
RAG’i “çalışıyor” yapmak kolaydır; “iyi çalışıyor” yapmak ise ayar ve tasarım ister. En kritik başlıklar:
-
Chunk boyutu ve overlap: Bağlamı korumak için
-
Top-k: Kaç parça getirileceği
-
Reranking: İlk sonuçları daha iyi bir sıralamayla iyileştirme
-
Metadata filtreleme: “Sadece 2025 dokümanları” gibi kısıtlar
-
Kaynak gösterimi (citations): Güven ve doğrulanabilirlik sağlar
-
Yetkilendirme: Her kullanıcı her dokümana erişmemeli
8) RAG’in Sınırları (Gerçekçi Olmak Gerek)
RAG çok faydalıdır; ancak mucize değildir:
-
Doküman yanlışsa cevap da yanlış olur
-
Kötü parse edilen tablolar/veriler kaliteyi düşürür
-
Çok adımlı hesaplama gerektiren işlerde ek mantık gerekebilir
-
“Güncel fiyat/stok/haber” gibi canlı veriler için dokümanın güncel olması şarttır (ya da canlı kaynak entegrasyonu gerekir)
9) Mini Örnek: Teknik Destek Dokümanlarıyla Chatbot
Elinizde yüzlerce PDF var: iade prosedürü, kurulum, garanti, servis yönergeleri…
Kullanıcı soruyor:
“Outlook’ta HTML mail bozuluyor. Önerdiğiniz yapı neydi?”
RAG akışı:
-
Soru embedding’e çevrilir
-
Vector DB, “Outlook HTML”, “table layout”, “inline CSS” geçen parçaları bulur
-
3–5 en alakalı parça modele verilir
-
Model, sadece bu parçalara dayanarak net yönerge üretir
-
İsterseniz kaynak da gösterir (“Doküman X / Bölüm Y”)
Sonuç: Vector DB + RAG Ne Sağlar?
-
LLM’i, kendi dokümanlarınızla konuşturur
-
“Kelime araması” yerine “anlam araması” yapar
-
Doğruluğu artırır, uydurma cevap riskini azaltır
-
Kurumsal bilgi tabanı, müşteri destek ve iç süreç otomasyonu için güçlü bir temel sunar
Sık Sorulan Kısa Sorular
RAG mi fine-tuning mi?
Genelde önce RAG. Çünkü dokümanlar değiştikçe sistemi güncellemek daha kolaydır. Fine-tuning daha maliyetlidir ve bakım ister.
Vector DB şart mı?
Az veri varsa zorunlu değildir; ancak veri büyüdükçe arama performansı ve kalite için pratikte şart hâline gelir.
RAG güvenli mi?
Doğru yetkilendirme, filtreleme ve logging ile güvenli hâle getirilir. Kurumsal kullanımda “erişim kontrolü” kritik bir şarttır.
Örnek:
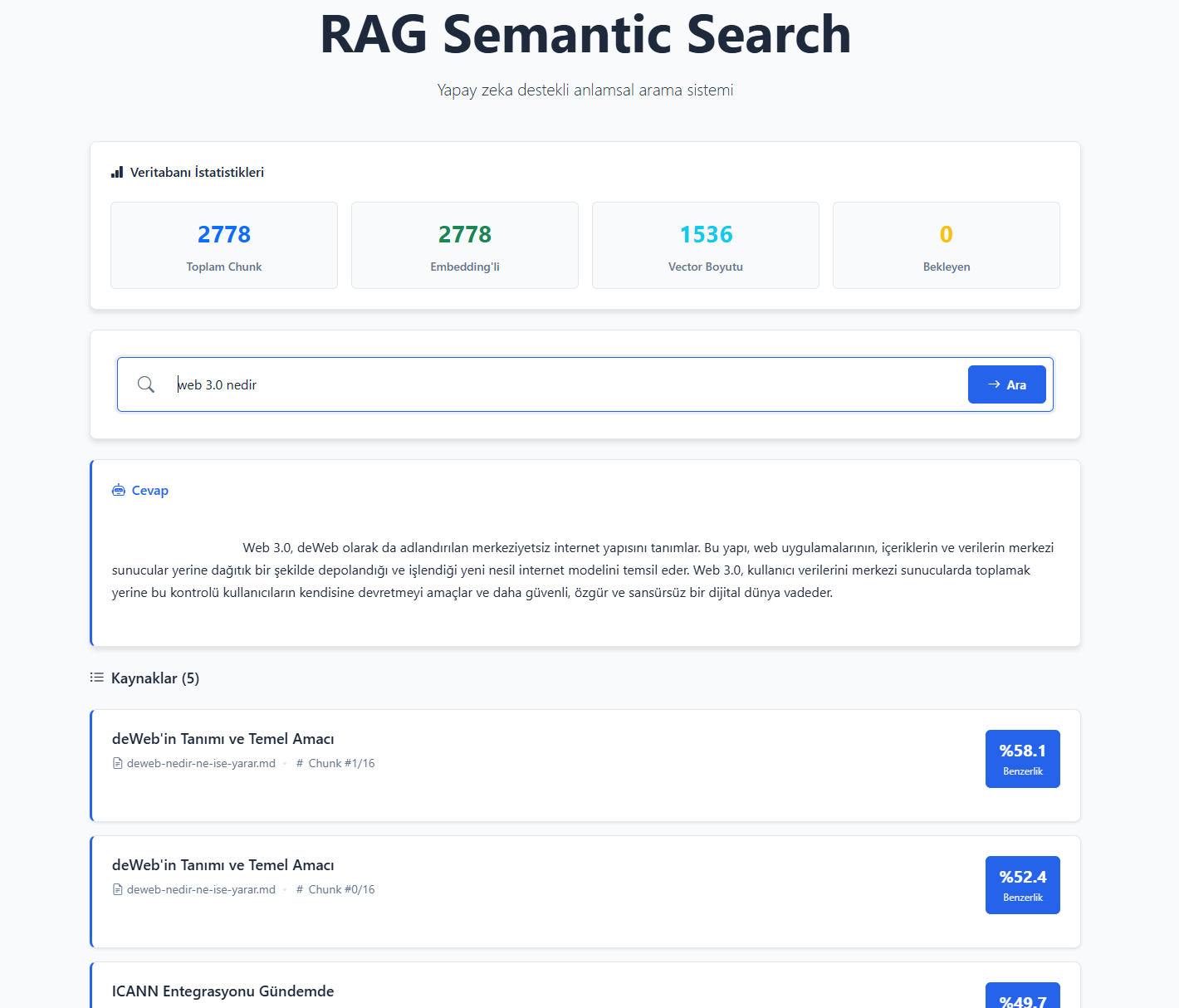
Örnek kodları ilerleyen süreçte GitHub hesabıma yükleyeceğim. Şimdilik, yazının hangi zeminde çıktı verdiğini daha iyi anlatabilmek için aşağıya ekran görüntülerini ekledim.
1-) PostgreSQL veritabanı tasarım çıktısı:
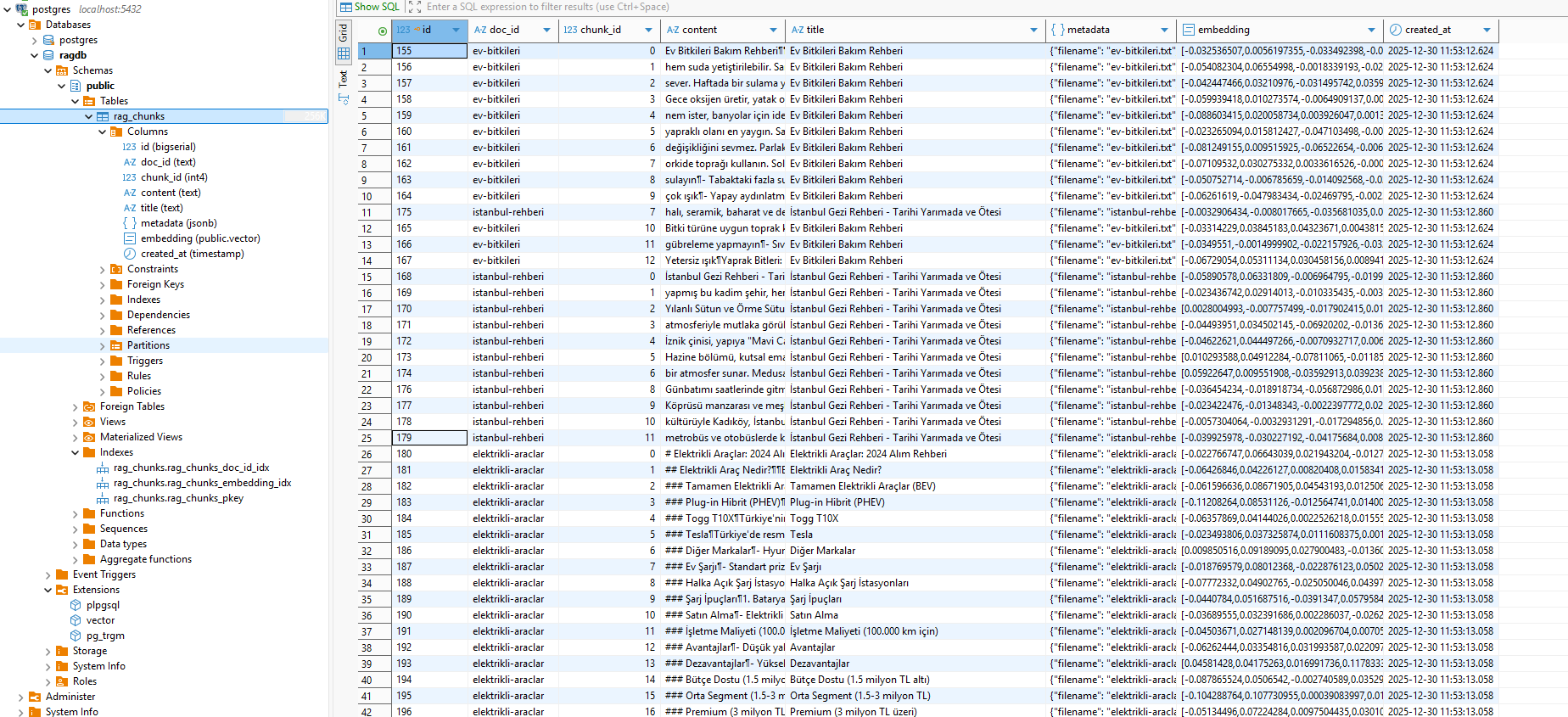
2-) C# .NET Core ile yazılmış app uygulaması çıktısı: