
Veriyi LLM'lere Hazırlamak: Docling ile Yapay Zeka Maceramın Başlangıcı
Yapay Zeka ile İlgili İlk Yazım: Docling ile Başlıyoruz
Açıkçası uzun süredir yapay zeka ile ilgili yazmak istiyordum ama ancak şimdi fırsat bulabildim. Bundan sonra burada bol bol yapay zeka, veri işleme, otomasyon ve LLM projeleriyle ilgili yazılar paylaşmayı planlıyorum. Bu ilk yazımda ise çok işime yarayan bir aracı tanıtmak istedim: Docling.
Neden Docling?
Yapay zeka tarafında çalışırken elimizdeki belgeler genelde PDF, Word, Excel, hatta ses kayıtları gibi ham halde duruyor. Oysa LLM modellerine doğru sorular sorabilmek veya onlara doğru verileri verebilmek için önce bu dosyaları anlamlı, yapılandırılmış verilere dönüştürmek gerekiyor. İşte Docling tam da burada devreye giriyor.
Docling Nedir?
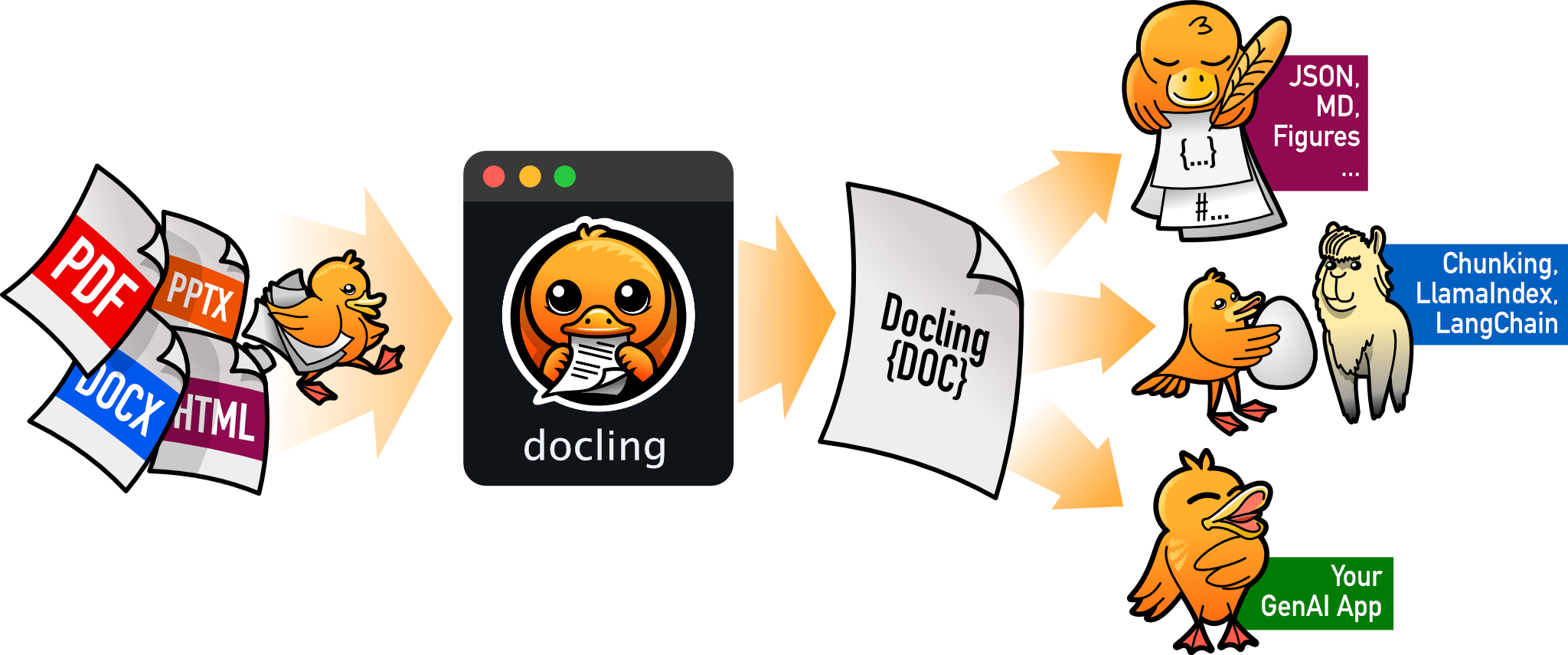
Docling, PDF, DOCX, XLSX, HTML, görseller ve ses dosyaları dahil birçok formatı okuyup içindeki bilgileri çıkaran açık kaynaklı bir Python kütüphanesi. Üstelik OCR (optik karakter tanıma) ve ASR (otomatik konuşma tanıma) desteğiyle taranmış belgeleri veya ses dosyalarını da metne dönüştürebiliyor. Çıktı olarak JSON, Markdown veya HTML gibi formatlar sunarak veriyi doğrudan yapay zeka modellerine beslemeye hazır hale getiriyor.
Kim Geliştirdi?
Docling aslında IBM’in uzun yıllardır üzerinde çalıştığı doğal dil işleme ve belge yönetimi araçlarından aldığı ilhamla, topluluk tarafından açık kaynaklı hale getirilmiş bir proje. IBM Research ekibinin açık kaynak katkıları sayesinde temel motorları (örneğin Tesseract tabanlı OCR genişletmeleri ve bazı NLP bileşenleri) oldukça güçlü. Proje şu anda bağımsız geliştiriciler ve veri bilimi meraklılarının katkılarıyla GitHub’da aktif bir şekilde büyüyor.
Yapay Zeka ile Bağlantısı Ne?
Yapay zekanın en önemli yakıtı veri. Eğer doğru, temiz ve yapılandırılmış veriye sahipsen modeller çok daha doğru sonuçlar üretir. Docling sayesinde karmaşık belgeleri saniyeler içinde parse edip JSON olarak almak mümkün. Böylece ister LangChain, ister Haystack, ister başka bir LLM tabanlı RAG pipeline olsun, hepsine hızlıca entegre edebiliyorsun.
Veriyi Serileştirip Başka Yerde Kullanmak
Docling’in en güzel yanlarından biri, elde ettiğin çıktıyı JSON ya da YAML gibi formatlarda serileştirebilmen. Bu sayede bu veriyi bir veri gölüne (Data Lake) kaydedebilir, NoSQL veritabanlarına (ör. MongoDB) atabilir ya da Kafka gibi mesaj kuyruklarıyla başka sistemlere akıtabilirsin. Özellikle ses kayıtlarını metne çevirip önemli cümleleri etiketlemek ve daha sonra bu transkriptleri analitik ya da chatbot sistemlerine beslemek büyük ufuk açıyor.
Benim İlk Deneyimim
Geçen hafta elimde yüzlerce PDF fatura vardı ve bunlardan başlıkları, tutarları, tarihleri çekip bir GPT pipeline’ına vermem gerekiyordu. Docling ile bunu birkaç satırlık kodla hallettim. Normalde belki günler sürecek bir işi birkaç dakikada tamamlamak büyük rahatlık. Ayrıca çıkan JSON veriyi MongoDB’ye kaydedip, sonradan analitik dashboard’larda (Metabase / Superset) canlı rapor olarak kullandım.
Sonuç
Bu yazıyla birlikte yapay zeka ile ilgili paylaşımlarıma başlamış oldum. İlerleyen günlerde Docling’in kod örneklerini, LangChain ve LlamaIndex ile entegrasyonlarını ve daha pek çok faydalı içeriği burada paylaşmayı düşünüyorum. Eğer sen de belgelerden hızlıca veri çıkarmak, bu verileri farklı sistemlerde kullanmak istiyorsan Docling’e mutlaka göz at derim.
GitHub sayfasına buradan ulaşabilirsin: https://github.com/docling-project/docling
Python kod örneği PDF serilize etme;
from docling import Document
# Bir PDF dosyasını okuyup JSON'a çeviriyoruz
doc = Document("faturalar/ocak2025.pdf")
data = doc.parse()
# Çıkan JSON'u kaydediyoruz
import json
with open("ocak2025.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("Fatura verileri başarıyla JSON olarak kaydedildi.")Serialize edilmiş JSON;
{
"filename": "ocak2025.pdf",
"pages": 12,
"extracted_text": "FATURA NO: 2025-001\nTarih: 03.01.2025\nToplam: 1450 TL\n...",
"entities": {
"invoice_number": "2025-001",
"date": "2025-01-03",
"total": "1450 TL"
}
}Ses Kayıtlarını Analiz Etmek
Docling’in bir diğer güçlü yanı ASR (Automatic Speech Recognition) desteği. Yani bir GSM şirketinin çağrı merkezi kayıtları gibi uzun ses kayıtlarını yükleyip, bunları metne çevirip sonra da üzerinde kelime veya konu bazlı analiz yapabiliyorsun.
Mesela diyelim ki binlerce çağrı kaydın var ve “iptal”, “şikayet”, “memnun değilim” gibi kelimeler geçtiğinde o görüşmeyi işaretlemek istiyorsun. Docling bu ses kaydını önce metne dönüştürüyor, sonra Python tarafında basit bir if "iptal" in transcript kontrolüyle bile alarm sistemleri veya raporlar oluşturabiliyorsun.
from docling import Document
import json
# Bir ses kaydını (.wav, .mp3 vs) yükleyip metne çeviriyoruz
call_doc = Document("cagrilar/abone_12345.wav")
transcript_data = call_doc.parse()
# Çıkan metni alıyoruz
transcript_text = transcript_data.get("text", "").lower()
# Basit kelime arama
if "iptal" in transcript_text or "şikayet" in transcript_text or "memnun değilim" in transcript_text:
print("⚠️ Uyarı: Bu çağrıda önemli kelimeler tespit edildi!")
else:
print("✅ Önemli bir ifade bulunamadı.")
# Sonuçları JSON olarak kaydediyoruz
with open("transcript_12345.json", "w", encoding="utf-8") as f:
json.dump(transcript_data, f, ensure_ascii=False, indent=2)
print("Transkript verisi JSON olarak kaydedildi.")
Bu çıktıyı yine JSON olarak kaydedip ileride NLP modellerine (ör. duygu analizi, niyet tanıma) besleyebilir veya direkt bir dashboard’a koyabilirsin. Böylece yüz binlerce saatlik çağrı kaydını hem hızlı hem de anlamlı şekilde tarayarak iş zekası süreçlerine entegre etmek mümkün hale geliyor.